
Anthropic的宝可梦人工智能基准测试
Anthropic最新的AI模型Claude 3.7 Sonnet通过征服经典Game Boy游戏《精灵宝可梦红版》,展现了非凡的能力,超越了之前的模型,并在一个创新的AI基准测试中展示了其先进的“扩展思维”能力。
Claude 3.7 玩宝可梦
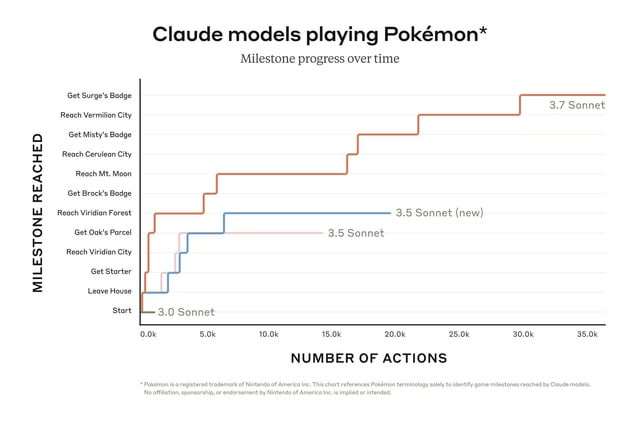
要玩《精灵宝可梦 红》,Claude 3.7 Sonnet 配备了基本的记忆功能、屏幕像素输入以及用于按键和导航游戏世界的功能调用1。这种设置使得 AI 能够通过数万次交互持续进行游戏,远远超出了其通常的上下文限制1。该模型的表现令人印象深刻,成功挑战并击败了三位精灵宝可梦道馆馆主,赢得了他们的徽章23。这一成就与 Claude 3.0 Sonnet 形成了鲜明对比,后者甚至无法离开真新镇的起始房屋,这突显了新版能力的显著进步45。
相较于以往模型的进步
Claude 3.7 Sonnet 相较于其前代产品,在人工智能能力方面实现了显著飞跃。该模型在《精灵宝可梦红》基准测试中的表现展示了其改进的推理和解决问题的能力12。与之前的版本不同,Claude 3.7 Sonnet 能够进行“扩展思维”,使其能够:
这一进步使模型能够更有效地处理复杂的多步骤问题,这从其成功导航《精灵宝可梦》游戏世界并击败多个道馆馆主中得到了证明56。“扩展思维”功能为 Claude 3.7 Sonnet 提供了更多计算资源和时间,以推理解决具有挑战性的问题,从而表现出更复杂和更具适应性的行为78。
扩展思维能力解析
Claude 3.7 Sonnet 的扩展思维能力,被描述为“串行测试时计算”,使其能够在生成最终输出之前执行多个连续的推理步骤1。这一高级功能使模型能够:
- 参与更复杂的问题解决
- 根据先前的结果调整策略
- 在任务过程中不断提高其性能
研究人员还探索了通过并行测试时计算来增强模型能力的方法,这涉及采样多个独立的思维过程并选择最佳的一个2。这一方法进一步扩展了 Claude 3.7 Sonnet 解决复杂问题和适应动态环境的能力,这在其成功通过《精灵宝可梦红》基准测试中得到了证明34。
游戏基准测试的重要性
像《精灵宝可梦 红》这样的游戏基准测试提供了清晰且可量化的指标,用于追踪人工智能的进展并比较不同的模型。这种方法加入了人工智能评估的更广泛趋势,其中象棋、围棋、《Dota 2》和《星际争霸 II》等游戏已被用来测试人工智能的能力12。这些游戏的复杂性——需要战略思维、资源管理以及适应动态环境——使它们成为评估人工智能推理和解决问题能力的理想选择34。通过征服《精灵宝可梦 红》,Claude 3.7 Sonnet 展示了其处理具有多种可能解决方案的开放式任务的能力,展现了该模型的多功能性及其在游戏场景之外的潜在应用。